|
Страница 1 из 3 Любая задача поиска в оперативном режиме может быть решена только агентом, выполняющим и вычисления, и действия, а не осуществляющим лишь вычислительные процессы. Предполагается, что агент обладает только описанными ниже знаниями. • Функция Actions (s), которая возвращает список действий, допустимых в состоянии s. • Функция стоимости этапа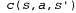 ; следует отметить, что она не может использоваться до тех пор, пока агент не знает, что результатом является состояние s'. ; следует отметить, что она не может использоваться до тех пор, пока агент не знает, что результатом является состояние s'. • Функция Goal-Test (s). Следует, в частности, отметить, что агент не может получить доступ к преемникам какого-либо состояния, иначе чем путем фактического опробования всех действий в этом состоянии. Например, в задаче с лабиринтом, показанной на рис. 4.12, агент не знает, что переход в направлении Up из пункта (1,1) приводит в пункт (1,2), а выполнив это действие, не знает, позволит ему действие Down вернуться назад в пункт (1,1). Такая степень неведения в некоторых приложениях может быть уменьшена, например, робот-исследователь может знать, как работают его действия по передвижению, и оставаться в неведении лишь в отношении местонахождения препятствий. Мы будем предполагать, что агент всегда может распознать то состояние, которое он уже посещал перед этим, кроме того, будем руководствоваться допущением, что все действия являются детерминированными. (Последние два допущения будут ослаблены в главе 17.) Наконец, агент может иметь доступ к некоторой допустимой эвристической функции h{s), которая оценивает расстояние от текущего состояния до целевого. Например, как показано на рис. 4.12, агент может знать местонахождение цели и быть способным использовать эвристику с манхэттенским расстоянием. Рис. 4.12. Простая задача с лабиринтом. Агент начинает движение с квадрата S и должен достичь квадрата G, но ничего не знает о самой среде
<< В начало < Предыдущая 1 2 3 Следующая > В конец >>
|
