|
Страница 2 из 2 Выражение Ρ (signal \ words) называется акустической моделью. Эта модель описывает звуки слов, например, говорит о том, что слово "ceiling" (потолок) начинается с мягкого звука "с" и звучит так же, как "sealing" (уплотнение). (Слова, звучащие одинаково, часто называют домофонами.) Выражение Ρ (words) принято называть языковой моделью. Эта модель задает априорную вероятность каждого фрагмента речи, например указывает, что последовательность слов "high ceiling" (высокий потолок) является гораздо более вероятной, чем "high sealing" (высокое уплотнение). Языковые модели, используемые в системах распознавания речи, обычно являются очень простыми. Модель двухсловных сочетаний, которая будет описана ниже в данном разделе, задает вероятность каждого слова, которое следует за каждым другим словом. Акустическая модель является гораздо более сложной. В ее основе лежит важное открытие, сделанное в области фонологии (науки о звуках устной речи), согласно которому во всех человеческих языках используется ограниченный набор звуков, называемых фонемами, количество которых находится в пределах от 40 до 50. Грубо говоря, фонема — это звук, который соответствует одной гласной или согласной букве, но существуют некоторые сложности; например, некоторые сочетания букв, такие как "th" и "ng", в английском языке соответствуют единственным фонемам, а некоторые буквы произносятся как разные фонемы в различных контекстах (в качестве примера можно указать букву "а" в словах "rat" и "rate"). В табл. 15.1 перечислены фонемы, используемые в английском языке, с примером для каждой из них. Итак, фонема — это наименьший фрагмент звукового сигнала, который имеет различимый смысл для людей, говорящих на конкретном языке. Например, в английском языке фонема "t" в слове "stick" является той же самой, что и фонема "t" в слове "tick", но в тайском языке они различаются как две отдельные фонемы. Таблица 15.1. Фонетический алфавит DARPA, или ARPAbet, в котором перечислены все фонемы, используемые в американском диалекте английского языка. Существует также несколько альтернативных систем обозначения фонем, включая международный фонетический алфавит (International Phonetic Alphabet — IPA), который описывает фонемы всех известных языков  Благодаря существованию фонем появляется возможность разделить акустическую модель на две части. Первая часть касается произношения и задает для каждого слова распределение вероятностей по возможным последовательностям фонем. Например, слово "ceiling" произносится как [s iy l ih ng]; или иногда как [s iy 1 ix ng], а иногда даже как [s iy 1 en]. Фонемы не являются непосредственно наблюдаемыми, поэтому, грубо говоря, речь может быть представлена как скрытая марковская модель, переменная состояния которой, , определяет, какая фонема произносится в момент времени t. , определяет, какая фонема произносится в момент времени t. Вторая часть акустической модели относится к тому способу, с помощью которого фонемы реализуются в виде акустических сигналов. Другими словами, переменная свидетельства Et для скрытой марковской модели задает наблюдаемые характеристики акустического сигнала в момент времени t, а акустическая модель определяет вероятность , где , где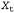 — текущая фонема. Эта модель позволяет также учитывать ударение, скорость и громкость речи и основана на методах из области обработки сигналов, позволяющих создавать описания сигналов, которые являются достаточно устойчивыми по отношению ко всем указанным влияниям. — текущая фонема. Эта модель позволяет также учитывать ударение, скорость и громкость речи и основана на методах из области обработки сигналов, позволяющих создавать описания сигналов, которые являются достаточно устойчивыми по отношению ко всем указанным влияниям. В оставшейся части данного раздела приведено описание указанных моделей и алгоритмов, которое построено от нижнего уровня к верхнему, начиная от акустических сигналов и фонем, проходя через отдельные слова и заканчивая целыми предложениями. В заключение будет показано, как происходит обучение всех этих моделей и насколько хорошо работают результирующие системы.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|