|
Страница 2 из 3 Очевидно, что требуется лучшее решение. Поэтому второе важное нововведение состоит в том, что множество выборок в основном следует формировать в областях пространства состояний, характеризующихся высокой вероятностью. Такую задачу можно выполнить, отбрасывая выборки, которые, согласно наблюдениям, имеют очень малый вес, вместе с тем увеличивая количество выборок, имеющих большой вес. Благодаря этому появляется возможность создавать множества выборок, которые остаются достаточно близкими к действительным данным. Если выборки рассматриваются как информационные ресурсы для моделирования распределения апостериорных вероятностей, то имеет смысл формировать больше выборок в тех областях пространства состояний, где апостериорная вероятность выше. Для решения именно этой задачи предназначено семейство алгоритмов, называемых алгоритмами фильтрации частиц. Метод фильтрации частиц действует следующим образом: прежде всего создается популяция из N выборок путем формирования выборок из распределения априорных вероятностей в момент времени О,  , затем, как описано ниже, для каждого временного интервала повторяется цикл обновления. , затем, как описано ниже, для каждого временного интервала повторяется цикл обновления. • Каждая выборка распространяется в прямом направлении путем формирования выборки значения переменной следующего состояния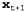 . Для этого в качестве выборки берется текущее значение . Для этого в качестве выборки берется текущее значение и используется модель перехода и используется модель перехода • Каждая выборка взвешивается с учетом правдоподобия, которое она присваивает новому свидетельству,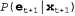 • В этой популяции выборок снова осуществляется формирование выборки для создания новой популяции из N выборок. Каждая новая выборка берется из текущей популяции; вероятность того, что будет получена конкретная выборка, пропорциональна ее весу. Данные о весах новых выборок уничтожаются. Этот алгоритм подробно показан в листинге 15.3, а пример его применения к сети DBN для задачи с зонтиком приведен на рис. 15.13. Листинг 15.3. Алгоритм фильтрации частиц, реализованный как рекурсивная операция обновления данных о состоянии (множества выборок). Каждый из этапов формирования выборок состоит в том, что формируется выборка значений соответствующих переменных временного среза в топологическом порядке, во многом так же, как и в процедуре Prior-Sample. Операция Weighted-Sample-with-Replacement может быть реализована так, чтобы она выполнялась за ожидаемое время O(N) 

Рис. 15.13. Пример применения цикла обновления алгоритма фильтрации частиц к сети DBN для задачи с зонтиком при N=10, в котором показаны популяции выборок в каждом состоянии: во время t обнаруживается, что 8 выборок показывают Rain, a 2 выборки показывают . Каждая из них распространяется в прямом направлении путем формирования выборок в следующем состоянии через модель перехода. Во время t+Ι обнаруживается, что 6 выборок показывают Rain, a 4 выборки показывают . Каждая из них распространяется в прямом направлении путем формирования выборок в следующем состоянии через модель перехода. Во время t+Ι обнаруживается, что 6 выборок показывают Rain, a 4 выборки показывают ; в момент времени t+Ι наблюдается ; в момент времени t+Ι наблюдается . Каждая выборка взвешивается с учетом ее правдоподобия применительно к этому наблюдению, как показывают размеры кружков (б); формируется новое множество из 10 выборок путем случайного выбора со взвешиванием из текущего множества, что приводит к получению 2 выборок, которые показывают Rain, и 8 выборок, которые показывают . Каждая выборка взвешивается с учетом ее правдоподобия применительно к этому наблюдению, как показывают размеры кружков (б); формируется новое множество из 10 выборок путем случайного выбора со взвешиванием из текущего множества, что приводит к получению 2 выборок, которые показывают Rain, и 8 выборок, которые показывают  (в) (в)
|