|
Страница 1 из 4 Для того чтобы поддерживать разговор с людьми, машина должна обладать способностью распознавать непрерывную речь, а не просто отдельные слова. На первый взгляд может показаться, что непрерывная речь представляет собой не что иное, как последовательность слов, к которой вполне можно применить алгоритм, приведенный в предыдущем разделе. Но этот подход оканчивается неудачей по двум причинам. Прежде всего, как уже было показано (с. 1), последовательность наиболее вероятных слов не является наиболее вероятной последовательностью слов. Например, в кинофильме "Take the Money and Run" (Бери деньги и беги) банковский кассир прочитал каракули в записке героя Вуди Аллена как слова "I have a gub" (У меня есть штука). Хорошая языковая модель должна была бы предложить в качестве намного более вероятной последовательности слова "I have a gun" (У меня есть пушка), даже несмотря на то, что последнее слово больше похоже на "gub", чем на "gun". Вторая проблема, с которой приходится сталкиваться при обработке непрерывной речи, связана с ^ сегментацией — с проблемой определения того, где оканчивается одно слово и начинается следующее. С этой проблемой знаком любой, кто пытался изучать иностранный язык с помощью прослушивания устной речи, — на первых порах кажется, что все слова сливаются друг с другом. Но постепенно иностранец учится выделять отдельные слова из беспорядочных звуков. В данном случае первые впечатления вполне оправдываются; спектрографический анализ показывает, что в беглой речи слова действительно следуют одно за другим без пауз между ними. Поэтому нам приходится учиться определять границы между словами, несмотря на отсутствие пауз. Начнем с языковой модели, назначение которой при распознавании речи состоит в определении вероятности каждой возможной последовательности слов. Используя запись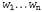 для обозначения строки из η слов и для обозначения строки из η слов и для обозначения i-ro слова в строке, можно составить выражение для вероятности некоторой строки с использованием цепного правила следующим образом: для обозначения i-ro слова в строке, можно составить выражение для вероятности некоторой строки с использованием цепного правила следующим образом: 
Большинство термов этого соотношения являются весьма сложными, а задача их оценки или вычисления является трудной. К счастью, возможно аппроксимировать эту формулу немного более простым соотношением и вместе с тем сохранить в целости значительную часть языковой модели. Одним из простых, широко применяемых и эффективных подходов является модель двухсловных сочетаний. В этой модели вероятность аппроксимируется вероятностью аппроксимируется вероятностью . Иначе говоря, в этом подходе принимается предположение о том, что для последовательностей слов можно использовать марковскую цепь первого порядка. . Иначе говоря, в этом подходе принимается предположение о том, что для последовательностей слов можно использовать марковскую цепь первого порядка.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|