|
Страница 4 из 4 Обратите внимание на то, что выше не было сказано, будто с помощью алгоритма Витерби "можно извлечь наиболее вероятную последовательность слов". Дело в том, что наиболее вероятная последовательность слов не обязательно является такой, которая содержит наиболее вероятную последовательность состояний. Это связано с тем, что вероятность последовательности слов представляет собой сумму вероятностей по всем возможным последовательностям состояний, совместимых с данной последовательностью слов. Например, сравнивая две последовательности слов, скажем "a back" (спина) и "aback" (абак), можно обнаружить, что имеется десять альтернативных последовательностей состояний для "a back", каждая из которых имеет вероятность 0,03, но только одна последовательность состояний для "aback" с вероятностью 0,20. Алгоритм Витерби выбирает "aback", но фактически более вероятной является последовательность "aback". На практике это затруднение не исключает возможности применения данного подхода, но является достаточно серьезным для того, чтобы были предприняты попытки использовать другие подходы. Наиболее часто применяемым из них является алгоритм декодера А*, в котором предусмотрено остроумное использование поиска А* (см. главу 4) для обнаружения наиболее вероятной последовательности слов. Идея этого алгоритма состоит в том, что каждая последовательность слов рассматривается как путь через граф, узлы которого обозначены метками в виде слов. Преемниками любого узла являются все слова, которые могут следовать за словом, являющимся меткой для этого узла; таким образом, граф для всех предложений с длиной, равной или меньшей п, имеет η уровней, причем каждый из этих уровней имеет максимальную ширину W, где W— количество возможных слов. При использовании двухсловной модели стоимость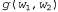 любой дуги между узлами с метками любой дуги между узлами с метками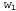 и и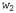 задается выражением задается выражением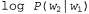 ; таким образом, общая стоимость пути, соответствующего некоторой последовательности, может быть представлена следующим образом: ; таким образом, общая стоимость пути, соответствующего некоторой последовательности, может быть представлена следующим образом: 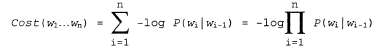
При использовании такого определения стоимости пути задача поиска кратчайшего пути становится полностью эквивалентной задаче поиска наиболее вероятной последовательности слов. Для того чтобы этот процесс был достаточно эффективным, необходимо также иметь хорошую эвристику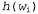 для оценки стоимости дополнения последовательности слов. Очевидно, что при этом подходе необходимо также учитывать, какая часть речевого сигнала еще не заменена словами из текущего пути. Тем не менее для решения этой задачи еще не были предложены эвристики, которые оказались бы особенно удачными. для оценки стоимости дополнения последовательности слов. Очевидно, что при этом подходе необходимо также учитывать, какая часть речевого сигнала еще не заменена словами из текущего пути. Тем не менее для решения этой задачи еще не были предложены эвристики, которые оказались бы особенно удачными.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|