|
Страница 2 из 2 Теперь можно приступить к оценке параметров модели перевода. Такую задачу можно решить, приняв довольно слабое начальное предположение, а затем постепенно его улучшая, как описано ниже. • Оценка начальной модели фертильности . Найдя французское предложение длины т, которое выравнивается с английским предложением длины л, будем рассматривать его как свидетельство того, что каждое французское слово имеет фертильность п/т. Рассмотрим все свидетельства во всех предложениях, чтобы получить распределение вероятностей фертильности для каждого слова. . Найдя французское предложение длины т, которое выравнивается с английским предложением длины л, будем рассматривать его как свидетельство того, что каждое французское слово имеет фертильность п/т. Рассмотрим все свидетельства во всех предложениях, чтобы получить распределение вероятностей фертильности для каждого слова. • Оценка начальной модели выбора слова . Рассмотрим все французские предложения, которые содержат, скажем, слова "brun". Слова, которые появляются наиболее часто в английских предложениях, выравниваемых с этими предложениями, являются наиболее вероятными буквальными переводами слова "brun". . Рассмотрим все французские предложения, которые содержат, скажем, слова "brun". Слова, которые появляются наиболее часто в английских предложениях, выравниваемых с этими предложениями, являются наиболее вероятными буквальными переводами слова "brun". • Оценка начальной модели смещения . Теперь, после получения модели выбора слова, воспользуемся ею, чтобы получить оценку модели смещения. Для каждого английского предложения длины п, которая выравнивается с французским предложением длины т, проанализировать каждое французское слово в предложении (в позиции i) и каждое английское слово в предложении (в позиции j), которое является наиболее вероятным вариантом выбора для французского слова, и рассматривать его как свидетельство для вероятности . Теперь, после получения модели выбора слова, воспользуемся ею, чтобы получить оценку модели смещения. Для каждого английского предложения длины п, которая выравнивается с французским предложением длины т, проанализировать каждое французское слово в предложении (в позиции i) и каждое английское слово в предложении (в позиции j), которое является наиболее вероятным вариантом выбора для французского слова, и рассматривать его как свидетельство для вероятности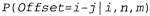 • Усовершенствование всех оценок. Воспользоваться алгоритмом ЕМ (expectation-maximization — ожидание-максимизация), чтобы усовершенствовать оценки. Скрытой переменной является вектор выравнивания слов между парами предложений, выровненными по предложениям. Этот вектор указывает для каждого английского слова позицию соответствующего французского слова во французском предложении. Например, может быть получено следующее: 
Вначале с использованием текущих оценок параметров создадим вектор выравнивания слов для каждой пары предложений. Это позволит нам получать лучшие оценки. Модель фертильности оценивается путем подсчета того, сколько раз один из элементов вектора выравнивания слов указывает на несколько слов или на нулевое количество слов. После этого в модели выбора слов могут рассматриваться только те слова, которые выровнены друг с другом, а не все слова в предложения, тогда как в модели смещений может рассматриваться каждая позиция в предложении для определения того, насколько часто она смещается в соответствии с вектором выравнивания слов. К сожалению, точно не известно, каковым является правильное выравнивание, а количество вариантов выравнивания слишком велико для того, чтобы перебрать их все. Поэтому мы вынуждены осуществлять поиск выравниваний с высокой вероятностью и взвешивать их по их вероятностям, собирая свидетельства для новых оценок параметров. Это все, что требуется для алгоритма ЕМ. На основании начальных параметров вычисляются выравнивания, а с помощью выравниваний уточняются оценки параметров. Такая процедура повторяется до полной сходимости.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|