|
Страница 1 из 2 При создании любой грамматики PCFG приходится преодолевать все сложности, связанные с формированием грамматики CFG, и наряду с этим решать проблему задания вероятностей для каждого правила. Такие обстоятельства наводят на мысль, что может оказаться более приемлемым подход, предусматривающий определение грамматики по имеющимся данным с помощью обучения, чем подход, основанный на инженерии знаний. Как и в случае распознавания речи, могут применяться данные двух типов — прошедшие и не прошедшие синтаксический анализ. Задача намного упрощается, если данные уже преобразованы в деревья с помощью синтаксического анализа лингвистами (или по меньшей мере носителями соответствующего естественного языка, прошедшими специальное обучение). Создание подобной текстовой совокупности требует больших капиталовложений, и в настоящее время самые крупные из таких совокупностей содержат "всего лишь" около миллиона слов. А если имеется некоторая совокупность деревьев, то появляется возможность создать грамматику PCFG путем подсчета (и сглаживания). Для этого достаточно просмотреть все узлы, в которых корневым является каждый нетерминальный символ, и создать правило для каждой отдельной комбинации дочерних элементов в этих узлах. Например, если какой-то символ NP появляется 100 тысяч раз и имеется 20 тысяч экземпляров NP со списком дочерних элементов [NP, PP], то создается правило 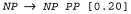
Если же текст не подвергнут синтаксическому анализу, то задача значительно усложняется. Это прежде всего связано с тем, что фактически приходится сталкиваться с двумя разными проблемами — определение с помощью обучения структуры грамматических правил и определение с помощью обучения вероятностей, связанных с каждым правилом (с аналогичным различием приходится сталкиваться при определении с помощью обучения параметров нейронных или байесовских сетей).
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|