|
Страница 1 из 5 До сих пор в этой главе предполагалось, что функции полезности и Q-функции, определяемые агентами с помощью обучения, представлены в табличной форме с одним выходным значением для каждого входного кортежа. Такой подход полностью себя оправдывает в небольших пространствах состояний, но время достижения сходимости и (в случае ADP) затраты времени на каждую итерацию быстро возрастают по мере увеличения размеров пространства. При использовании тщательно управляемых, приближенных методов ADP иногда удается справиться с задачами по обработке 10 000 или большего количества состояний. Этого достаточно для двухмерных вариантов среды, подобных лабиринтам, но более реальные миры далеко выходят за эти пределы. Шахматы и нарды представляют собой крошечные подмножества реального мира, но даже их пространства состояний содержат примерно от состояний. Даже само предположение о том, что нужно было бы посетить все эти состояния, для того чтобы узнать с помощью обучения, как играть в такую игру, является абсурдным! состояний. Даже само предположение о том, что нужно было бы посетить все эти состояния, для того чтобы узнать с помощью обучения, как играть в такую игру, является абсурдным! Один из способов справиться с этими задачами состоит в использовании средств функциональной аппроксимации; такая рекомендация просто означает, что для функции следует применять представления любого рода, отличные от таблиц. Такое представление рассматривается как аппроксимированное, поскольку может оказаться, что истинная функция полезности или Q-функция не может быть точно представлена в выбранной форме. Например, в главе 6 была описана функция оценки для шахмат, представленная в виде взвешенной линейной функции от множества характеристик (или базисных функций)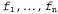 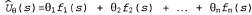
Алгоритм обучения с подкреплением позволяет определить с помощью обучения такие значения параметров , что функция оценки , что функция оценки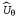 аппроксимирует истинную функцию полезности. Вместо использования, скажем, аппроксимирует истинную функцию полезности. Вместо использования, скажем,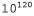 значений в таблице, такой аппроксиматор функции характеризуется, допустим, п=20 параметрами, а это просто колоссальное сжатие. В частности, хотя никто не знает истинную функцию полезности для шахмат, никто и не считает, что ее можно точно представить с помощью 20 чисел. Но если эта аппроксимация является достаточно качественной, агент все равно приобретает возможность достичь поразительных успехов в шахматах. значений в таблице, такой аппроксиматор функции характеризуется, допустим, п=20 параметрами, а это просто колоссальное сжатие. В частности, хотя никто не знает истинную функцию полезности для шахмат, никто и не считает, что ее можно точно представить с помощью 20 чисел. Но если эта аппроксимация является достаточно качественной, агент все равно приобретает возможность достичь поразительных успехов в шахматах.
<< В начало < Предыдущая 1 2 3 4 5 Следующая > В конец >>
|