|
Страница 5 из 5 где f(u,n) называется функцией исследования. Эта функция определяет компромисс между жадностью (предпочтениями, отданными высоким значениям и) и любопытством (предпочтениями, отданными низким значениям л, характеризующим действия, которые еще не были опробованы достаточно часто). Функция f(u,n) должна увеличиваться в зависимости от и и уменьшаться в зависимости от п. Безусловно, что существует много возможных функций, которые соответствуют этим условиям. Одним из особенно простых определений такой функции является следующее: 
где — оптимистическая оценка наилучшего возможного вознаграждения, которое может быть получено в любом состоянии; — оптимистическая оценка наилучшего возможного вознаграждения, которое может быть получено в любом состоянии; — постоянный параметр. Результатом применения такой функции становится то, что агент пытается проверить каждую пару "состояние-действие" по меньшей мере — постоянный параметр. Результатом применения такой функции становится то, что агент пытается проверить каждую пару "состояние-действие" по меньшей мере раз. раз. Тот факт, что в правой части уравнения 21.5 присутствует величина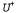 , а не U, очень важен. Может вполне оказаться так, что по мере развития процесса исследования в большом количестве попыток будут опробованы состояния и действия, находящиеся недалеко от начального состояния. Если бы использовалась более пессимистическая оценка полезности, U, то агент вскоре стал бы не склонным проводить дальнейшее исследование среды. А применение оценки , а не U, очень важен. Может вполне оказаться так, что по мере развития процесса исследования в большом количестве попыток будут опробованы состояния и действия, находящиеся недалеко от начального состояния. Если бы использовалась более пессимистическая оценка полезности, U, то агент вскоре стал бы не склонным проводить дальнейшее исследование среды. А применение оценки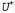 означает, что выгоды от исследования среды распространяются в обратном направлении от границ неисследованных регионов, поэтому получают больший вес действия, ведущие к неисследованным регионам, а не просто действия, которые сами по себе остаются малоизученными. Эффект использования такой исследовательской стратегии наглядно показан на рис. 21.5, который демонстрирует более быструю сходимость к оптимальной производительности в отличие от жадного подхода. Способ действий, очень близкий к оптимальному, обнаруживается всего лишь после 18 попыток. Обратите внимание на то, что сами оценки полезности не сходятся так же быстро. Это связано с тем, что агент довольно рано прекращает исследование частей пространства состояний, не предоставляющих вознаграждения, и в дальнейшем посещает их только "по случаю". Но благодаря такому подходу агент приобретает идеальное понимание того, что не следует задумываться о точных значениях полезностей состояний, которые, как ему известно, являются нежелательными и которых можно избежать. означает, что выгоды от исследования среды распространяются в обратном направлении от границ неисследованных регионов, поэтому получают больший вес действия, ведущие к неисследованным регионам, а не просто действия, которые сами по себе остаются малоизученными. Эффект использования такой исследовательской стратегии наглядно показан на рис. 21.5, который демонстрирует более быструю сходимость к оптимальной производительности в отличие от жадного подхода. Способ действий, очень близкий к оптимальному, обнаруживается всего лишь после 18 попыток. Обратите внимание на то, что сами оценки полезности не сходятся так же быстро. Это связано с тем, что агент довольно рано прекращает исследование частей пространства состояний, не предоставляющих вознаграждения, и в дальнейшем посещает их только "по случаю". Но благодаря такому подходу агент приобретает идеальное понимание того, что не следует задумываться о точных значениях полезностей состояний, которые, как ему известно, являются нежелательными и которых можно избежать. 
Рис. 21.5. Производительность агента ADP, проводящего исследование среды с использованием параметров : оценки изменения полезностей для избранных состояний во времени (а); среднеквадратичная ошибка в значениях полезностей и связанная с ней убыточность стратегии (б) : оценки изменения полезностей для избранных состояний во времени (а); среднеквадратичная ошибка в значениях полезностей и связанная с ней убыточность стратегии (б)
<< В начало < Предыдущая 1 2 3 4 5 Следующая > В конец >>
|