|
Страница 1 из 2 Индуктивный вывод грамматики представляет собой задачу определения с помощью обучения грамматики на основе данных. Очевидно, что попытка решить такую задачу вполне оправдана, поскольку практика показала, насколько сложно конструировать грамматику вручную, а в Internet можно бесплатно получить миллиарды готовых примеров фрагментов речи. Но такая задача является сложной, поскольку пространство возможных грамматик бесконечно, а проверка того, что данная конкретная грамматика производит необходимое множество предложений, требует больших вычислительных затрат. Одной из интересных моделей является система Sequitur [1122]. Для нее не требуется никаких входных данных, кроме одного отрывка текста (который не требуется даже предварительно разбивать на предложения). Эта система формирует грамматику в очень специализированной форме — грамматику, которая производит лишь единственную строку, а именно первоначальный текст. Иначе к анализу результатов этой системы можно подойти таким образом, что Sequitur в процессе обучения определяет лишь такой объем грамматических правил, который является достаточным для синтаксического анализа данного текста. Ниже приведена приемлемая разбивка с помощью скобок, обнаруженная этой системой для одного предложения из более крупного текста с информацией о новостях. [Most Labour][sentiment [[would still][favor the] abolition]][[of [the House]][of Lords]] В этом фрагменте правильно выделены такие составляющие, как словосочетание РР "of the House of Lords", хотя и допущены отклонения от традиционного метода анализа, например артикль "the" включен в одну группу с предшествующим глаголом, а не со следующим существительным. Система Sequitur основана на той идее, что "хорошая грамматика — компактная грамматика". В частности, в ней принудительно применяются следующие два ограничения. Во-первых, ни одна пара смежных символов не должна появляться в грамматике больше одного раза. Если пара символов А в появляется в правой части нескольких правил, то эту пару следует заменить новым нетерминальным символом, назвать его, допустим, С и ввести правило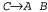 . Во-вторых, каждое правило должно использоваться по меньшей мере дважды. Если некоторый нетерминальный символ С появляется в грамматике только один раз, то необходимо удалить правило для С и заменить его единственное вхождение правой частью данного правила. Эти два ограничения применяются в процедуре жадного поиска, которая сканирует текст слева направо, инкрементно наращивая в ходе этого грамматику и налагая ограничения, как только появляется такая возможность. В табл. 22.8 показано, как действует этот алгоритм применительно к входному тексту "abcdbcabcd". Алгоритм восстанавливает оптимально компактную грамматику для этого текста. . Во-вторых, каждое правило должно использоваться по меньшей мере дважды. Если некоторый нетерминальный символ С появляется в грамматике только один раз, то необходимо удалить правило для С и заменить его единственное вхождение правой частью данного правила. Эти два ограничения применяются в процедуре жадного поиска, которая сканирует текст слева направо, инкрементно наращивая в ходе этого грамматику и налагая ограничения, как только появляется такая возможность. В табл. 22.8 показано, как действует этот алгоритм применительно к входному тексту "abcdbcabcd". Алгоритм восстанавливает оптимально компактную грамматику для этого текста.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|