|
Страница 1 из 4 Подход, основанный на обучении с подкреплением, предложил Тьюринг [1519], [1520], но он не был убежден в его общей эффективности и писал, что "использование наказаний и вознаграждений в лучшем случае может составлять лишь часть процесса обучения". По-видимому, одним из первых успешных исследований по машинному обучению была работа Артура Самюэла [1349]. Хотя эта работа не была основана на теоретическом фундаменте и имела целый ряд недостатков, она содержала большинство современных идей в области обучения с подкреплением, включая применение временной разности и функциональной аппроксимации. Примерно в то же время исследователи в области теории адаптивного управления Видроу и Хофф [1587], опираясь на работу Хебба [638], занимались обучением простых сетей с помощью дельта-правила. (Долго существовавшие неправильные представления о том, что обучение с подкреплением является частью проблематики нейронных сетей, могло быть вызвано тем, что связь между этими научными областями установилась так рано.) Как метод обучения с подкреплением на основе аппрокси-матора функции может также рассматриваться работа Мичи и Чамберса [1046], посвященная системе "тележка-шест". Психологические исследования в области обучения с подкреплением начались гораздо раньше; хороший обзор по этой теме приведен в [653]. Непосредственные свидетельства того, как осуществляется обучение с подкреплением у животных, были получены в исследованиях поведения пчел, связанного с добычей пищи; достоверно обнаружен нейронный аналог структуры передачи сигнала вознаграждения в виде крупного нейронного образования, связывающего рецепторы органов взятия нектара непосредственно с двигательной корой [1070]. Исследования, в которых используется регистрация активности отдельной клетки, показали, что допаминовая система в мозгу приматов реализует нечто напоминающее обучение на основе стоимостной функции [1369]. Связь между обучением с подкреплением и марковскими процессами принятия решений была впервые отмечена в [1580], но разработка методов обучения с подкреплением в рамках искусственного интеллекта началась с исследований, проводимых в Массачусетсском университете в начале 1980-х годов [76]. Хороший исторический обзор подготовлен Саттоном [1477]. Уравнение 21.3, приведенное в этой главе, представляет собой частный случай общего алгоритма ΊD(λ) Саттона при λ=0. В алгоритме TD(λ) обновляются значения всех состояний в последовательности, ведущей вплоть до каждого перехода, на величину, которая уменьшается в зависимости от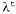 для состояний, отстоящих на t шагов в прошлое. Алгоритм TD(1) идентичен правилу Видроу-Хоффа, или дельта-правилу. Бойян [162], опираясь на [170], доказал, что в алгоритме TD(λ) и связанных с ним алгоритмах результаты, полученные опытным путем, используются неэффективно; по сути они представляют собой алгоритмы оперативной регрессии, которые сходятся гораздо медленнее, чем алгоритмы автономной регрессии. Предложенный Бойяном алгоритм LSTD(A) представляет собой оперативный алгоритм, позволяющий достичь таких же результатов, как и алгоритм автономной регрессии. для состояний, отстоящих на t шагов в прошлое. Алгоритм TD(1) идентичен правилу Видроу-Хоффа, или дельта-правилу. Бойян [162], опираясь на [170], доказал, что в алгоритме TD(λ) и связанных с ним алгоритмах результаты, полученные опытным путем, используются неэффективно; по сути они представляют собой алгоритмы оперативной регрессии, которые сходятся гораздо медленнее, чем алгоритмы автономной регрессии. Предложенный Бойяном алгоритм LSTD(A) представляет собой оперативный алгоритм, позволяющий достичь таких же результатов, как и алгоритм автономной регрессии.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|