|
Пассивный обучающийся агент руководствуется постоянно заданной стратегией, которая определяет его поведение, а активный агент должен сам принимать решение о том, какие действия следует предпринять. Начнем с описания агента, действующего с помощью адаптивного динамического программирования, и рассмотрим, какие изменения необходимо внести в его проект, чтобы он мог функционировать с учетом этой новой степени свободы. Прежде всего агенту потребуется определить с помощью обучения полную модель с вероятностями результатов для всех действий, а не просто модель для заданной стратегии. Для этой цели превосходно подходит простой механизм обучения, используемый в алгоритме Passive-ADP-Agent. Затем необходимо принять в расчет тот факт, что агент должен осуществлять выбор из целого ряда действий. Полезности, которые ему потребуются для обучения, определяются оптимальной стратегией; они подчиняются уравнениям Беллмана, приведенным на с. 824, которые мы еще раз приведем ниже для удобства. 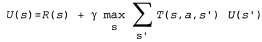 (21.4) (21.4)
Эти уравнения могут быть решены для получения функции полезности U с помощью алгоритмов итерации по значениям или итерации по стратегиям, приведенных в главе 17. Последняя задача состоит в определении того, что делать на каждом этапе. Получив функцию полезности U, оптимальную для модели, определяемой с помощью обучения, агент может извлечь информацию об оптимальном действии, составляя одношаговый прогноз для максимизации ожидаемой полезности; еще один вариант состоит в том, что если используется итерация по стратегиям, то оптимальная стратегия уже известна, поэтому агент должен просто выполнить действие, рекомендуемое согласно оптимальной стратегии. Но действительно ли он должен выполнять именно это действие?
|