|
Страница 1 из 3 В этом разделе будет описан исчерпывающий подход к проектированию агентов для частично наблюдаемых, стохастических вариантов среды. Как показано ниже, основные элементы этого проекта должны быть уже знакомы читателю. • Модели перехода и наблюдения представлены в виде динамических байесовских сетей (см. главу 15). • Динамическая байесовская сеть дополняется узлами принятия решений и узлами полезности, по аналогии с теми, которые использовались в сетях принятия решений в главе 16. Результирующая модель называется динамической сетью принятия решений (Dynamic Decision Network — DDN). • Для учета данных о каждом новом восприятии и действии и для обновления представления доверительного состояния используется алгоритм фильтрации. • Решения принимаются путем проектирования в прямом направлении возможных последовательностей действий и выбора наилучших из этих последовательностей. Основное преимущество использования динамической байесовской сети для представления модели перехода и модели восприятия состоит в том, что такая сеть позволяет применять декомпозицию описания состояния на множество случайных переменных во многом аналогично тому, как в алгоритмах планирования используются логические представления для декомпозиции пространства состояний, применяемого в алгоритмах поиска. Поэтому проект агента представляет собой практическую реализацию агента, действующего с учетом полезности, который был кратко описан в главе 2. Поскольку в этом разделе будут использоваться динамические байесовские сети, вернемся к системе обозначений главы 15, где символом обозначается множество переменных состояния во время t, a обозначается множество переменных состояния во время t, a — переменные свидетельства. Таким образом, там, где до сих пор в этой главе использовалось обозначение — переменные свидетельства. Таким образом, там, где до сих пор в этой главе использовалось обозначение (состояние во время t), теперь будет применяться обозначение (состояние во время t), теперь будет применяться обозначение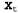 . Для обозначения действия во время t будет использоваться запись . Для обозначения действия во время t будет использоваться запись , поэтому модель перехода T(s, a, s' ) представляет собой не что иное, как , поэтому модель перехода T(s, a, s' ) представляет собой не что иное, как ), а модель наблюдения 0(s, о) — то же, что и ), а модель наблюдения 0(s, о) — то же, что и ). Для обозначения вознаграждения, полученного во время t, будет применяться запись ). Для обозначения вознаграждения, полученного во время t, будет применяться запись , а для обозначения полезности состояния во время t — запись , а для обозначения полезности состояния во время t — запись . При использовании такой системы обозначений динамическая сеть принятия решений принимает вид, подобный показанному на рис. 17.7. . При использовании такой системы обозначений динамическая сеть принятия решений принимает вид, подобный показанному на рис. 17.7.  Рис. 17.7. Универсальная структура динамической сети принятия решений. Переменные с известными значениями выделены затенением. Текущим временем является t, а агент должен решить, что делать дальше, т.е. выбрать значение для At. Сеть развернута в будущее на три этапа и представляет будущее вознаграждение, а также полезность состояния на горизонте прогноза
<< В начало < Предыдущая 1 2 3 Следующая > В конец >>
|