|
Страница 2 из 3 Динамические сети принятия решений позволяют получить краткое представление крупных задач POMDP, поэтому могут использоваться в качестве входных данных для любого алгоритма POMDP, включая те из них, которые относятся к методам итерации по значениям и итерации по стратегиям. В этом разделе мы сосредоточимся на прогностических методах, которые проектируют последовательности действий в прямом направлении от текущего доверительного состояния во многом таким же образом, как и алгоритмы ведения игр, описанные в главе 6. Сеть, приведенная на рис. 17.7, спроектирована в будущее на три этапа; неизвестными являются все текущие и будущие решения, а также будущие наблюдения и вознаграждения. Обратите внимание на то, что сеть включает узлы вознаграждений для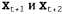 , но для , но для — только узел полезности. Это связано с тем, что агент должен максимизировать (обесцениваемую) сумму всех будущих вознаграждений, а полезность — только узел полезности. Это связано с тем, что агент должен максимизировать (обесцениваемую) сумму всех будущих вознаграждений, а полезность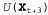 представляет и вознаграждение, относящееся к представляет и вознаграждение, относящееся к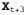 , и все будущие вознаграждения. Как и в главе 6, предполагается, что значение полезности U доступно только в некоторой приближенной форме, поскольку, если бы были известны точные значения полезности, то не было бы необходимости заглядывать вперед на глубину больше 1. , и все будущие вознаграждения. Как и в главе 6, предполагается, что значение полезности U доступно только в некоторой приближенной форме, поскольку, если бы были известны точные значения полезности, то не было бы необходимости заглядывать вперед на глубину больше 1. На рис. 17.8 показана часть дерева поиска, соответствующего приведенной на рис. 17.7 сети DDN, развернутой в будущее на три этапа. Каждый из узлов, обозначенных треугольником, представляет собой доверительное состояние, в котором агент принимает решение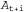 для 1 = 0,1,2,.... Узлы, обозначенные кружками, соответствуют выборам, сделанным средой, а именно тому, какие получены результаты наблюдений для 1 = 0,1,2,.... Узлы, обозначенные кружками, соответствуют выборам, сделанным средой, а именно тому, какие получены результаты наблюдений . Обратите внимание на то, что в этой сети нет узлов жеребьевки, соответствующих результатам действий; это связано с тем, что обновление доверительного состояния для любого действия является детерминированным, независимо от фактического результата. . Обратите внимание на то, что в этой сети нет узлов жеребьевки, соответствующих результатам действий; это связано с тем, что обновление доверительного состояния для любого действия является детерминированным, независимо от фактического результата. Доверительное состояние каждого обозначенного треугольником узла можно вычислить, применив алгоритм фильтрации к ведущей к нему последовательности наблюдений и действий. Таким образом, в алгоритме учитывается тот факт, что для принятия решения о выполнении действия агент должен иметь доступные результаты восприятия агент должен иметь доступные результаты восприятия , даже несмотря на то, что во время t он не знает, какими будут эти результаты восприятия. Благодаря этому агент, действующий на основе теории принятия решений, автоматически учитывает стоимость информации и выполняет действия по сбору информации, когда это потребуется. , даже несмотря на то, что во время t он не знает, какими будут эти результаты восприятия. Благодаря этому агент, действующий на основе теории принятия решений, автоматически учитывает стоимость информации и выполняет действия по сбору информации, когда это потребуется. 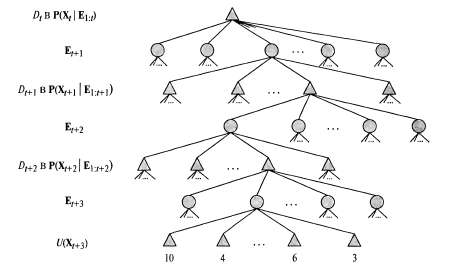
Рис. 17.8. Часть прогностического решения для сети DDN, приведенной на рис. 17.7
|